1. Elasticsearch 설치(8.17.4)
1) 아래의 링크로 접속해 최신 Elasticsearch 설치 파일을 다운로드.
https://www.elastic.co/kr/downloads/elasticsearch
Download Elasticsearch
Download Elasticsearch or the complete Elastic Stack (formerly ELK stack) for free and start searching and analyzing in minutes with Elastic....
www.elastic.co
Windows 선택 후 다운로드

2) 적절한 경로에 압축 풀기
3) 배치 파일 실행


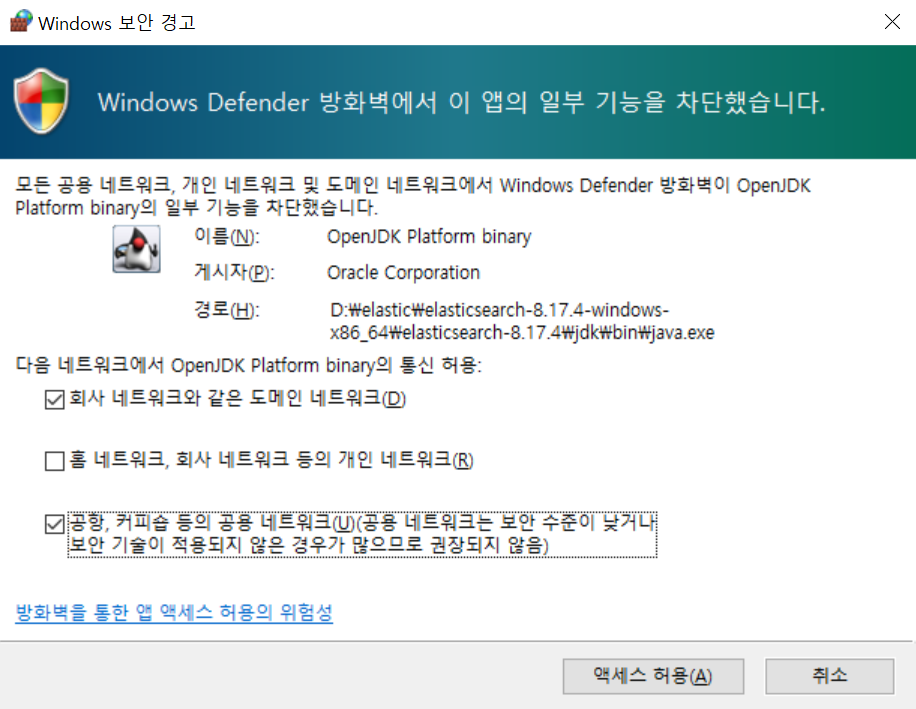
액세스 허용 클릭
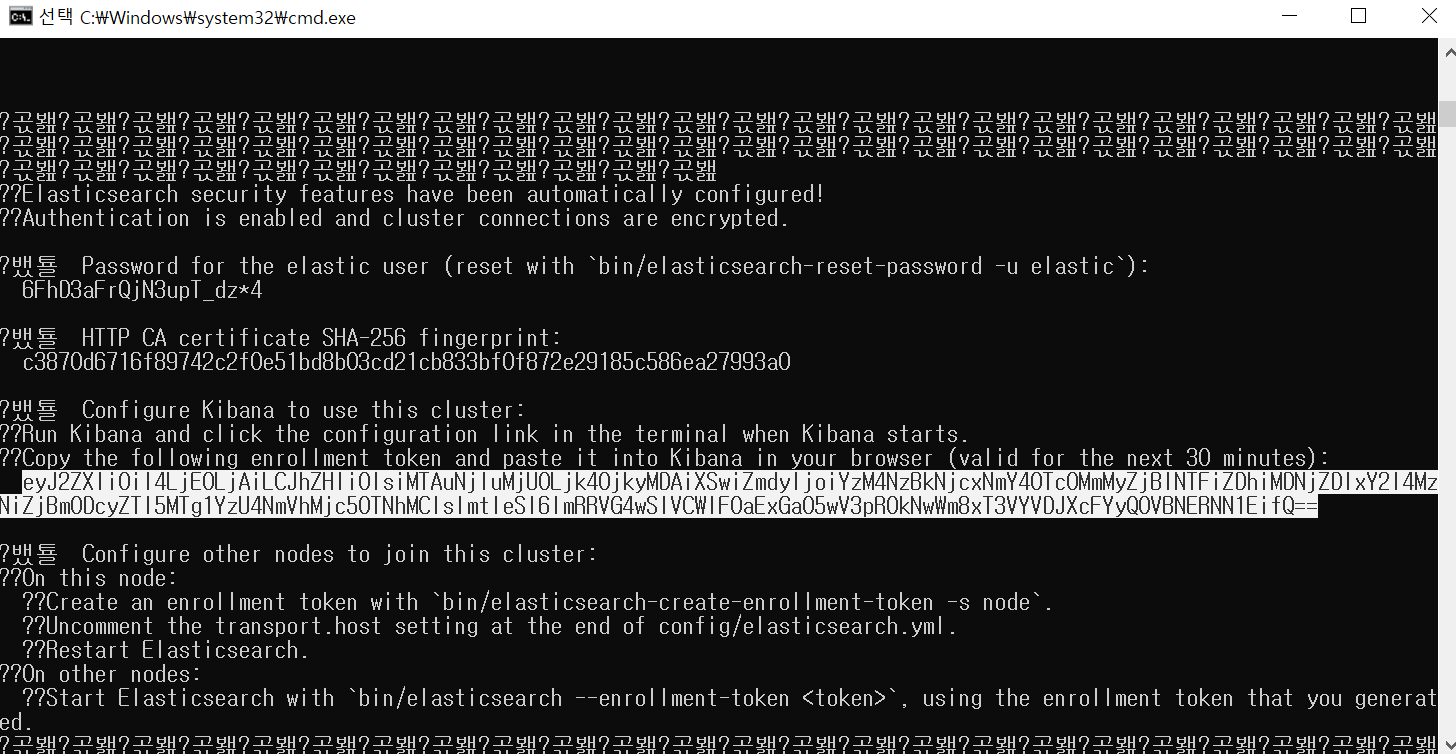
4) Elasticsearch 설치 확인
cmd 창 중간 쯤에 패스워드 확인 후 따로 기록합니다.

인터넷 브라우저를 열고
localhost:9200 접속
- 사용자 이름 : elastic
- 비밀번호 : 위에서 조회한 패스워드

아래와 같이 정보가 표시되었다면 정상적으로 설치된 것입니다.

2. Kibana 설치(8.17.4)
1) 아래 링크로 접속해 마찬가지로 Windows 용 설치 파일을 다운로드 받습니다.
https://www.elastic.co/kr/downloads/kibana
Download Kibana Free | Get Started Now
Download Kibana or the complete Elastic Stack (formerly ELK stack) for free and start visualizing, analyzing, and exploring your data with Elastic in minutes....
www.elastic.co

2) 적절한 경로에 압축 풀기
3) 배치 파일 실행
4) Kibana 설치 확인
elasticsearch 배치 파일을 실행한 cmd 창에서 비밀번호를 확인한 위치 밑에 토큰 값을 확인합니다.
인터넷 브라우저를 열고
localhost:5601 접속
아래와 같은 화면이 표시되었다면 정상 설치 완료.

'AI > Elastic Search' 카테고리의 다른 글
| [Elasticsearch] 무료 평가 체험판 시작하기 (0) | 2025.03.26 |
|---|---|
| [Elasticsearch] 쿼리 시 유사성 측정 방법(코사인 유사성, 점 곱 유사성, 유클리드 거리) (0) | 2025.03.25 |
| [Elasticsearch] 벡터 데이터베이스 : Vector Search (인덱싱 / 쿼리) (0) | 2025.03.25 |
| [Elasticsearch] 벡터 임베딩(=임베딩)이란? (0) | 2025.03.25 |
| [Elasticsearch] 벡터 데이터베이스(Vector Database) (0) | 2025.03.25 |